이 네트워크의 구조를 설명하자면요.
기존에는 학습에 단독 네트워크를 활용했다면, GAN은 한 쌍의 대립 네트워크를 구성하여 이를 이용해 학습시키는 것입니다.
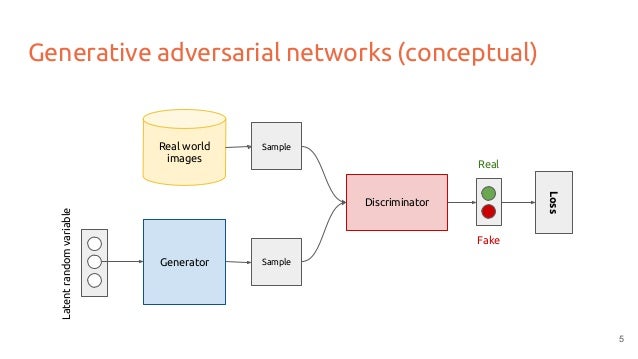
(출처 - slideshare)
위 그림은 GAN의 핵심 구조를 나타낸 것인데요.
한 쪽은 Generator, 즉 '생성'하는 네트워크구요. 다른 한쪽은 Discriminator, 즉 Generator에서 생성한 결과물을 가지고 참과 거짓을 구분하는 역할을 담당합니다.
discriminator가 내부적으로 참과 거짓을 가려내는 방법은 보통 수학적인 data distribution을 사용하여 training data와 유사한 일관성을 가졌는지 구분하는 방식을 사용하는데요. 일관성이 있으면 생성결과물을 참으로 분류하고 아니면 거짓으로 분류합니다.
fig1
여기서 Generator(G)는 최대한 Real을 생성하는 확률을 높이기 위해 훈련되며, discriminator(D)는 최대한 fake 판정 성공 비율을 늘리기 위해 훈련됩니다. 그래서 이를 min - max problem이라고 해요.
보통 실제적인 활용 측면에서는, min- max problem에서 Generator가 최종적으로는 좀 더 우세하도록 트레이닝하는데, 이 경우에 아직 정확한 nash equilibrium 에 대해서는 계산이 어려워 논문마다 각기 다른 접근법을 사용하고 있습니다.
일반적으로 사용되는 global optimum(최적해)찾기 문제에 대해서는 이 쪽에 잘 나와있는 듯 하구요.
http://jaejunyoo.blogspot.com/2017/01/generative-adversarial-nets-2.html

fig2
이 그림은 GAN의 학습변동을 보여 주고 있는데요.
fig2에서 까만 점선은 fig1의 E, 녹색 실선은 G, 파란 점선은 D를 나타냅니다.
a는 기본 상태
b는 분포 확률에 따라 Discriminator을 훈련시키는 단계
c는 Generator를 훈련시켜 구분하기 어렵게 하는 단계
d는 Generator가 data distribution상으로 training set과 완전히 같은 분포로 result를 형성하여 참과 거짓을 구분하지 못하게 된 상태를 의미하며 GAN 응용의 최종적인 목표단계입니다.
훈련 방식은 크게 feature matching과 minibatch discrimination이 존재하는데요.
대개 Generator가 학습할 때마다 매번 다른 이미지를 출력할 수 있도록 훈련시키는 데 중점을 두고 있습니다.
feature matching은, Generator를 훈련시킬 때 윈래 데이터와 유사한 값을 생성하도록 학습시키는 것이구요.
minibatch discrimination은, batch내의 데이터들을 다 다르게 조정하도록 하여 다른 입력에 대해 항상 다른 출력값을 가지도록 만드는 것입니다. 이렇게 조정함으로서 Generator가 학습할 수 있도록 하는 것이지요.
근래에는 이를 이용하여 자동적으로 색채 디자인?을 수행하는 논문조차 나와있더군요.
https://arxiv.org/abs/1611.07004
여기 가면 테스트도 해보실 수 있구요.
https://affinelayer.com/pixsrv/

댓글 없음:
댓글 쓰기
글에 대한 의문점이나 요청점, 남기고 싶은 댓글이 있으시면 남겨 주세요. 단 악성 및 스팸성 댓글일 경우 삭제 및 차단될 수 있습니다.
모든 댓글은 검토 후 게시됩니다.