word2vec 이란, 문맥속 단어 자체에 일종의 경향성을 수치화한 vector를 부여하여 단어의 의미를 컴퓨터가 수치적으로 계산하고 분석하여 활용할 수 있도록 한 것이에요. 예컨데 단어들에 대해 수치화된(vector)값을 부여하여 특성들을 분석해놓고, 이를 이용하여 단어 간 관계.. 예컨데 한국 - 서울, 미국 - ?이라고 하면, 여기서 선행 관계를 벡터를 이용해 분석하여 ?에 들어가는 적절한 단어(워싱턴DC)를 찾아 내는 것이지요.
이러한 시도 자체는 아주 예전부터 있었으나 기술의 부족으로 인해 실질적으로 활용되지는 못하다가 2000년대에 들어서야 NNLM(Feed-Forward Neural Net Language Model )이라고 불리는 초기적인 방법이 제안되었어요.
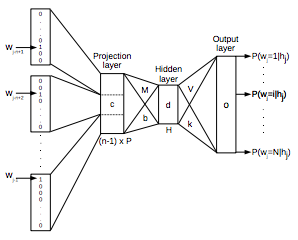
NNLM구조
이의 구조를 간단하게 해석하자면 여러 개의 단어를 input layer로 입력받은 뒤 hidden layer로 처리하여 단어가 어떤 카테고리에 속해 있는지에 대해 확률을 출력하게 됩니다. 이 모델은 현재 인공신경망 자연어 처리의 제일 기본이 되는 모델이며, 다른 모델들은 이를 이용해서 변형한 것입니다.
이 모델을 발전시켜 2013년 Mikolov가 구글에서 제시한 모델이 바로 word2vec로서
CBOW, skip-gram모델 등 학습 성능을 개선할 수 있는 학습모델을 제시하였습니다.
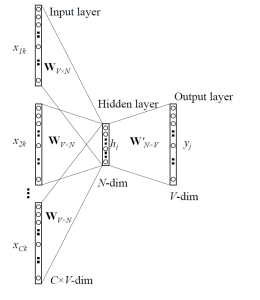
CBOW모델은 Input Layer, Projection Layer, Output Layer로 이루어져 있는데요. hidden layer로 projection한 뒤 weight를 반영한 계산 결과물의 에러를 반영하는 식으로 학습을 진행한다고 하네요.

skip- gram 모델은 CBOW와는 형식상 반대 보양이지만, 실제 작동기작은 상당히 유사해서, 단어 하나를 가지고 주변 단어들의 등장여부를 분석하여 잘 안 나오는 단어가 멀리 떨어져있다고 가정하는 방식을 사용한다고 하네요.
단어의 종류는 굉장히 많기에, 단어를 처리하는 과정에서 말 그대로 엄청난 연산량이 요구되기에 일반적인 방법으로는 처리하기 어렵습니다. 그렇기에 이 과정에서는 binary tree를 활용한 hierarchical softmax나, 단어들 중 일부만 골라 계산하는 샘플링 방식을 활용하는 negative sampling등의 방식을 사용한다고 합니다.
이러한 자연어 처리 기술은, 주로 자동화된 챗봇이나 언어 번역과 같은 분야에서 주로 활용되는 추세에 있어요.
관련 참고 사이트
word2vec 이론 관련 정리 - https://shuuki4.wordpress.com/2016/01/27/word2vec-%EA%B4%80%EB%A0%A8-%EC%9D%B4%EB%A1%A0-%EC%A0%95%EB%A6%AC/
word2vec 학습 방식 - https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/
word2vec 학습 방식 - https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/03/30/word2vec/

댓글 없음:
댓글 쓰기
글에 대한 의문점이나 요청점, 남기고 싶은 댓글이 있으시면 남겨 주세요. 단 악성 및 스팸성 댓글일 경우 삭제 및 차단될 수 있습니다.
모든 댓글은 검토 후 게시됩니다.